We would like to investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. This problem is “translating” an input image into a corresponding output image (across representations). This is shown in figure below:
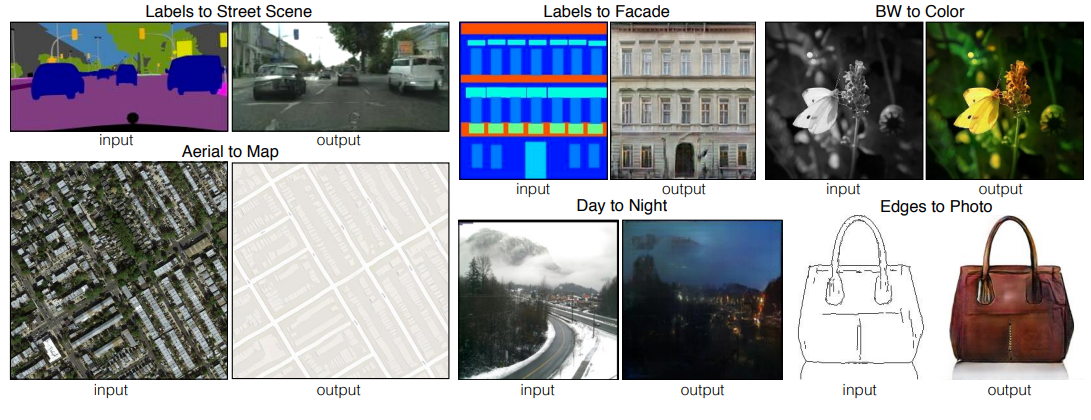
The figure shows labels to street scene, labels to façade, black-n-white to color, aerial to map, day to night and edges to photo. Traditionally each of these tasks has been tacked with separate special-purpose machinery. This approach would develop a common framework for all these problems.
Conditional GANs
As GANs learn a generative model of data, conditional GANs learn a conditional generative model because we would like to condition on an input image and generate a corresponding output image.
Structured Loss
Image-to-image translation are often formulated as per-pixel classification/regression which treat the output space as “unstructured” (each pixel is considered conditionally independent from all others given the input image). cGANs learn a structured loss which penalizes the joint configuration of the output.
Method
GANs learn a mapping from random noise vector $z$ to output image $y$, i.e. $G:z\to y$. In cGANs it learns a mapping from observed image $x$ and random noise vector $z$ to $y$, i.e. $G:\{x,z\}\to y$
Objective
The objective of cGANs is:
where $G$ tries to minimize this against adversary $D$ that tries to maximize it, i.e.
In case of unconditional variant we have:
We also add a $L_1$ distance which has been found to be beneficial (instead $L_2$ is, but we use $L_1$ because it encourages less blurring). The final objective is
Network Architectures
The generator and discriminator use modules of the form convolution-BatchNorm-ReLu
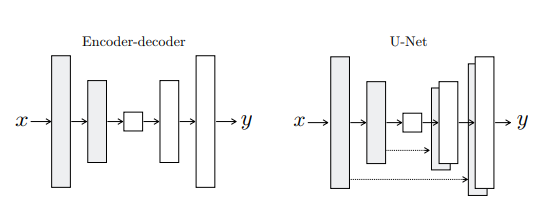
Generator with skips
-
In this problem we are translating high-res input grid to high-res output grid which differ in surface appearance. Therefore both structures are roughly aligned to each other. Similar to many previous approaches here input is passed through a series of layers that down-sample until a bottleneck layer when the process is reversed.
-
There is some low-level information shared between input and output so we shuttle this information directly across the net.
-
To give the generator a means to circumvent the bottleneck for information we add skip connections following the general shape of “U-Net”.
Markovian discriminator

It has been known that $L2$ and $L1$ loss produce blurry images. Though these losses fail to grasp finer detail they do help capturing low frequencies. So we need to only take care of high-frequency structure, whereas $L1$ term will take care of low-frequency structure.
We use a PatchGAN that will only penalize the structure at scales of patches where discriminator only classifies at each of the $N\times N$ patches which is then averaged to get the output of $D$.
Optimizations
- We alternate between one step of gradient descent on $D$, then on $G$.
- Instead of minimizing $\log (1-D(x, G(x, z)))$ we maximize $\log D(x, G(x, z))$
- We divide the objective by 2 while optimizing $D$ that slows the rate at which $D$ learns relative to $G$.
- We use minibatch SGD and use Adam solver.